Embrace Zero Trust with Ease
redefine what it means to have your services managed
Quickly gain the protective power of Zero Trust with ON2IT’s Zero Trust as a Service
ON2IT’s Zero Trust as a Service delivers a new approach to managed cybersecurity services, designed for prevention, enabling you to embrace Zero Trust with ease and 24/7 support from our comprehensive SOC team. We are Zero Trust.
Built on the Zero Trust strategy, Zero Trust As A Service delivers the industry’s strongest protection against cyber threats as a managed service.
the only mssp with zero trust as a service
The pillars of your cyberdefense

Zero Trust
INNOVATORS SINCE 2005
ON2IT has designed and implemented Zero Trust environments for hundreds of organizations. Lieuwe-Jan Koning (CTO) and Yuri Bobbert (CISO) are world renowned Zero Trust experts.
AUXO™
PROPRIETARY ZERO TRUST platform
The first to offer the best of SIEM, SOAR, and MDR: the all-in-one automated managed service platform integrating our cutting-edge Eventflow™ technology for superior breach protection.
mSOC™
CERTIFIED 24/7 managed SOC
Focus on your core business while the mSOC™ functions as your fully operational security conscience. Leverage the experience, skills, and latest tooling ON2IT’s Zero Trust experts offer.
zero trust Prevents
Data Breaches
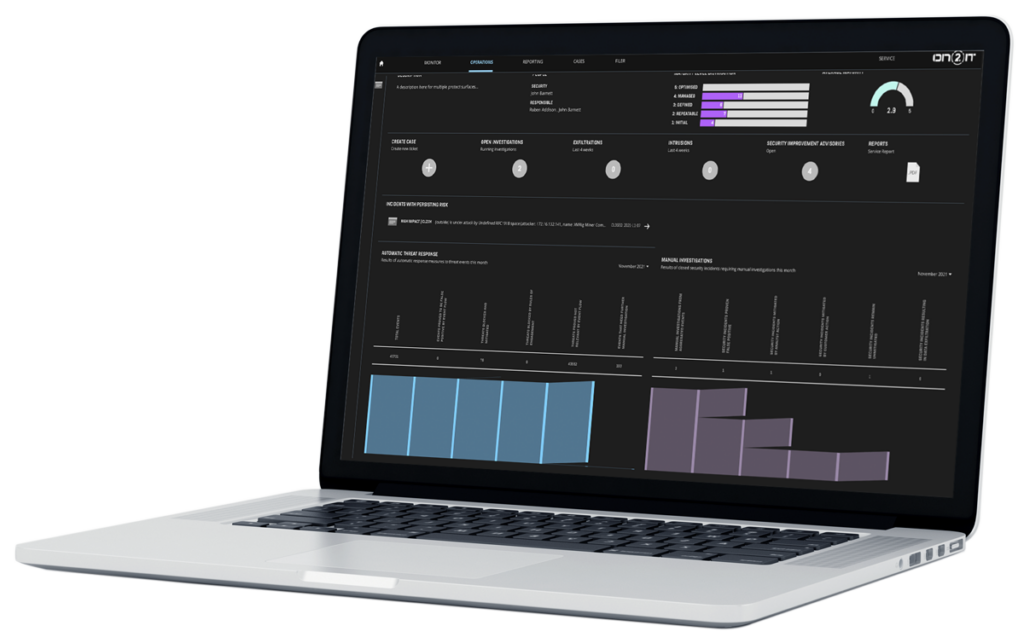
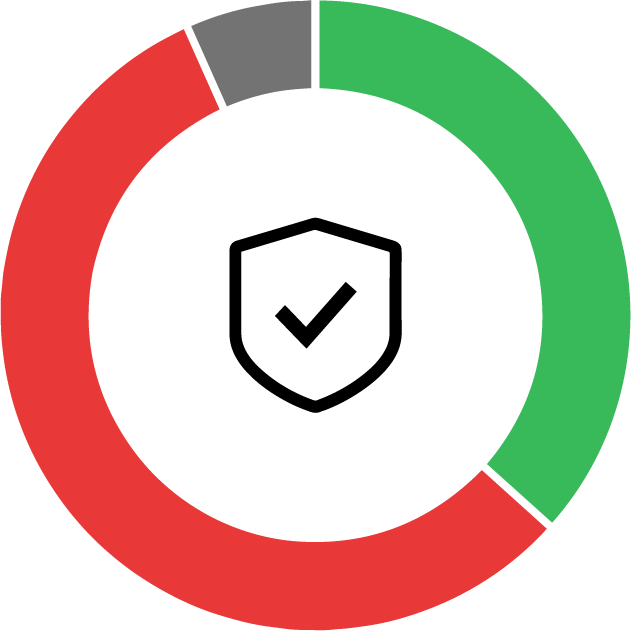
Secure your critical assets with unsurpassed protect surface management
Using a Zero Trust strategy reduces your overall attack surface by segmenting your infrastructure in much smaller protect surfaces, optimized to safeguard your valuable resources against known and unknown threats.
Zero Trust as a Service includes:
fast track your zero trust journey
Utilizing the NSTAC recommended Five-Step Methodology

Define the protect surface
Map the transaction flows

Build a Zero Trust architecture

Create a Zero Trust policy
Monitor and maintain the network
The Five-Step Methodology is recommended by the NSTAC (The President’s National Security Telecommunications Advisory Committee) in the Zero Trust and Trusted Identity Management draft report of March 2022.
BETTER PREVENTION,
Less staff
Our integrated AUXO™ solution to dramatically decrease your workload and free up valuable resources: Eventflow™
With our AI-based Eventflow™ automation, only one in every 100,000 events need manual inspection, so you get fewer alerts instead of more.
Eventflow™